Hadoop集群环境搭建1
这个配置方法并不是很完善,,另外了些新的搭建方法,详情请见Hadoop集群环境搭建2</font>
1.准备
4台linux虚拟机(master、node1、node2、node3)安装过程不再赘述,提醒:在安装时候选择带GNOME桌面更加方便,也可以单独配置一台之后,克隆虚拟机,如果使用虚拟机克隆的方法搭建,参考一下文章
https://blog.csdn.net/qq_44373783/article/details/103960578
https://www.cnblogs.com/pcxie/p/7747317.html
https://www.cnblogs.com/laov/p/3421479.html
用到虚拟机克隆:https://blog.csdn.net/huanbia/article/details/51658439
(1)更改各主机名字
为了能够更方便的识别主机,将四台虚拟机的名字分别修改为master、node1、node2、node3
注意切换到root账户下
1 | cd /etc //进入配置目录 |

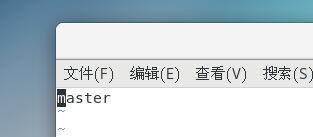
点击Esc,在:wq保存退出
另外三个虚拟机同样操作
(2)开启主机的DHCP模式,自动获取ip地址
1 | cd /etc/ysconfig/network-scripts |
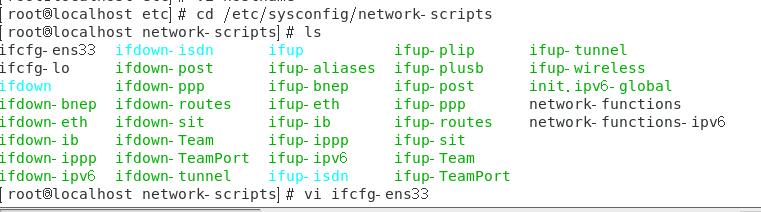
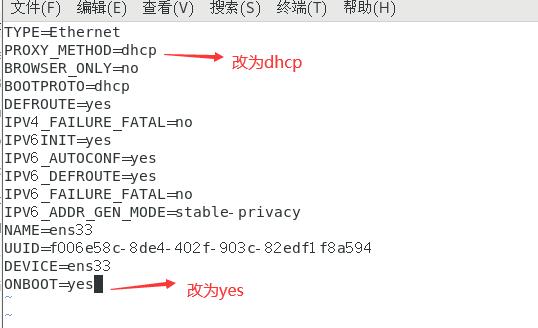
重启网卡
1 | service network restart |
在四台虚拟机中分别进行以上操作
之后输入ip addr,记下四个虚拟机的ip地址
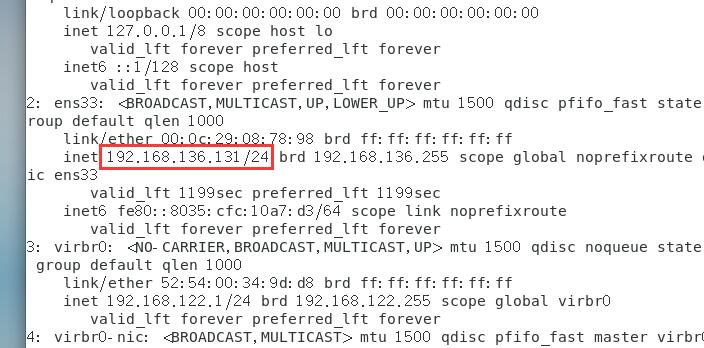
| 主机名 | ip地址 |
|---|---|
| master | 192.168.136.131 |
| node1 | 192.168.136.130 |
| node2 | 192.168.136.129 |
| node3 | 192.168.136.132 |
(3)配置hosts
master
配置hosts主要是为了让机器能够相互识别
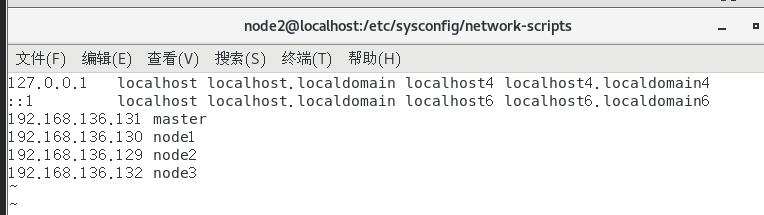
注:hosts文件是域名分析文件,在hosts文件内配置了ip地址和主机名的对应关系,配置之后,通过主机名,电脑就可以定位到相应的ip地址
1 | vi /etc/hosts |
在hosts文件中输入一下内容:
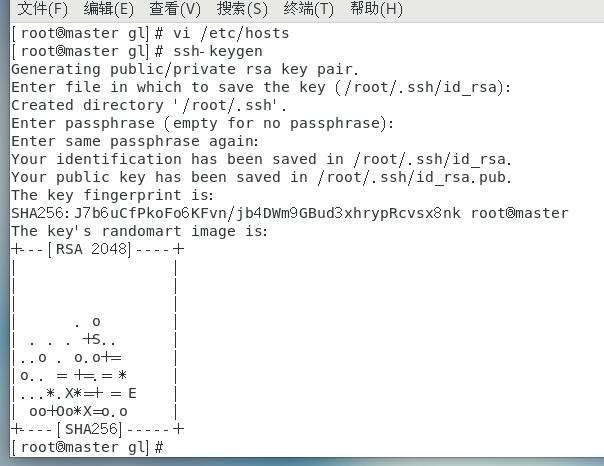
(4)在master节点中:
1 | ssh-keygen |
ssh一路回车
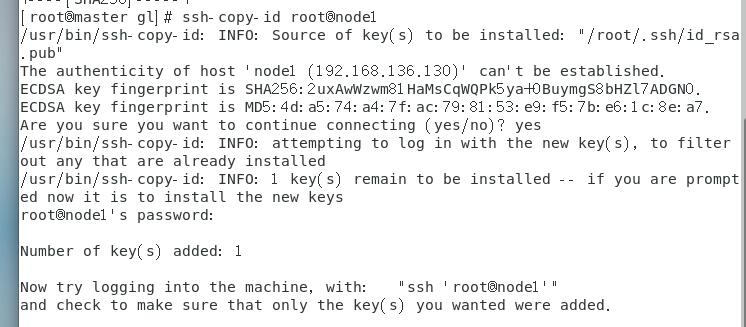
使用如下命令将公钥复制到node1、node2和node3节点中:
1 | ssh-copy-id root@node1 |
再分别执行
1 | ssh-copy-id root@localhost |
输入ssh node1实验是否能免密登陆
注意:ssh免密设置后会在如下目录生成四个文件

2.JDK环境安装
(1)新建目录放至JDK
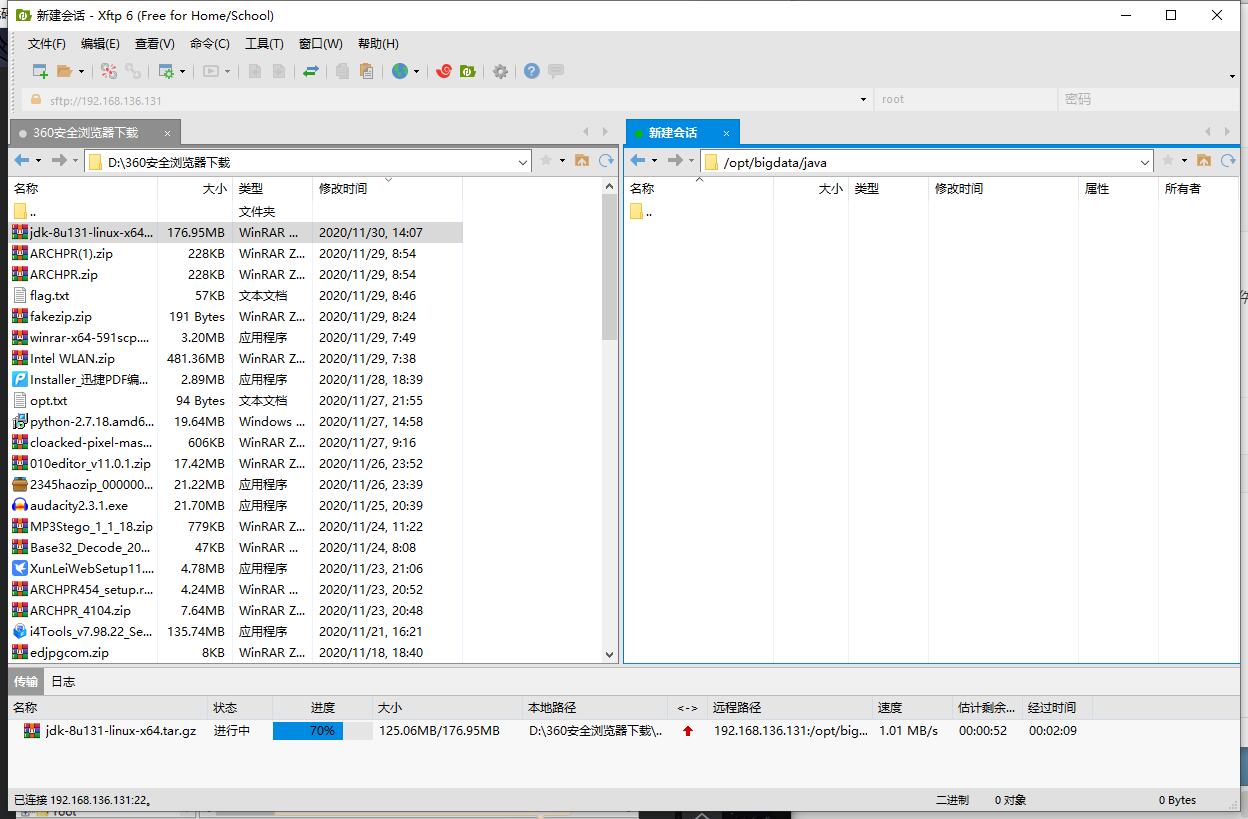
在master中新建目录/opt/bigdata/java
1 | mkdir /opt/bigdata/java |
此目录下存放hadoop大数据所需要的环境包
将下载好的JDK包上传至master主机中
(2)解压JDK
1 | tar -zxvf jdk-8u131-linux-x64.tar.gz |
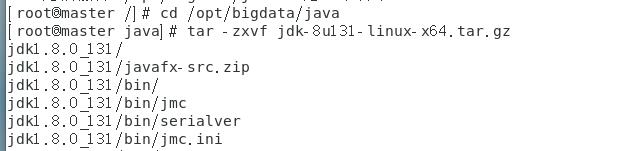
(3)配置JDK环境变量
1 | vi /etc/profile |
根据自己的路径在末尾添加以下内容
1 | export JAVA_HOME=/opt/bigdata/java/jdk1.8.0_131 |
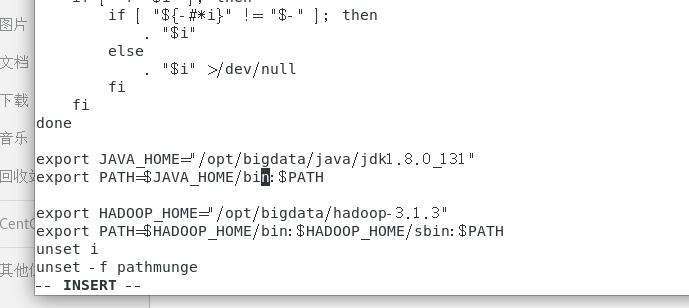
1 | source /etc/profile |

(4)JDK拷贝到其他节点
在node1节点新建目录/opt/bigdata/java
1 | mkdir /opt/bigdata/java |
然后在master节点下
1 | scp -r /opt/bigdata/java/jdk1.8.0_131 root@node1:/opt/bigdata/java |
配置环境变量
在其他节点进行类似操作3.Hadoop安装
(1)安装
1 | tar -zxvf hadoop.tar.gz |
(2)将hadoop文件拷贝到其他节点
master
1 | scp -r /opt/bigdata/hadoop-3.1.3/etc/hadoop root@node1:/opt/bigdata/hadoop-3.1.3/etc/hadoop |
1 | scp -r /opt/bigdata/hadoop-3.1.3 root@node2:/opt/bigdata |
1 | scp -r /opt/bigdata/hadoop-3.1.3 root@node3:/opt/bigdata |
然后在node1、node2、node3中配置环境变量
(3)修改配置文件
使用以下命令,进入目录
1 | cd /opt/bigdata/hadoop-3.1.3/etc/hadoop |
我们需要 core-site.xml、hadoop-env.sh、hdfs-site.xml、mapred-site.xml进行配置
1.配置hadoop-env.sh
1 | vi hadoop-env.sh |
查找JAVA_HOME配置的位置
1 | :/export JAVA_HOME |
输入JAVA_HOME的绝对路径
export JAVA_HOME=/opt/bigdata/jdk1.8.0_131(把前面的#注释去掉)

2.配置core-site.xml
3.配置hdfs-site.xml
4.配置mapred-site.xml
5.配置yarn-site.xml
6.配置workers
7.复制配置文件
把master节点的配置复制到其他node节点
1 | scp /opt/bigdata/hadoop-3.1.3/etc/hadoop/* node1:/opt/bigdata/hadoop-3.1.3/etc/hadoop |
(4)配置hadoop环境
1 | vi /etc/profile |
在文件末尾添加
1 |
|
执行
1 | source /etc/profile |
[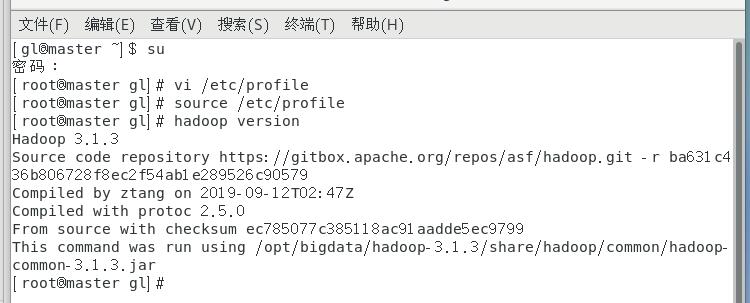 ](
](
(5)检查hadoop搭建情况
1.关闭防火墙(四台虚拟机)
按顺序执行以下命令
使用命令:systemctl status firewalld.service 查看防火墙状态
使用命令:systemctl stop firewalld.service 关闭防火墙
使用命令:systemctl disable firewalld.service 禁止防火墙
2.格式化namenode
第一次启动集群,在master虚拟机的hadoop-3.1.3目录下执行
1 | bin/hdfs namenode -format |
3.启动
1 | start-all.sh |
如果启动报错
1 | [root@iZbp153yczpm4pp9pjs0u3Z sbin]# start-all.sh |
需要进入hadoop安装目录下的sbin文件夹
1.对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
1 | HDFS_DATANODE_USER=root |
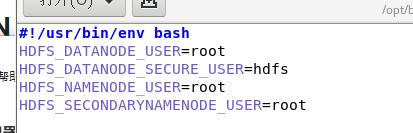
2、对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
1 |
|
重新启动即可
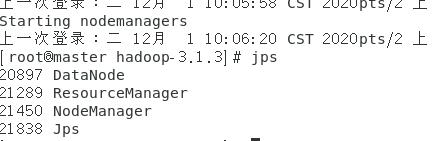
4.检查进程
启动之后,在每台虚拟机输入以下命令
1 | jps |
master
node1

node2
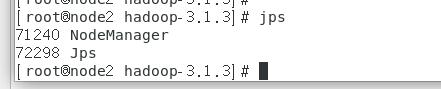
node3

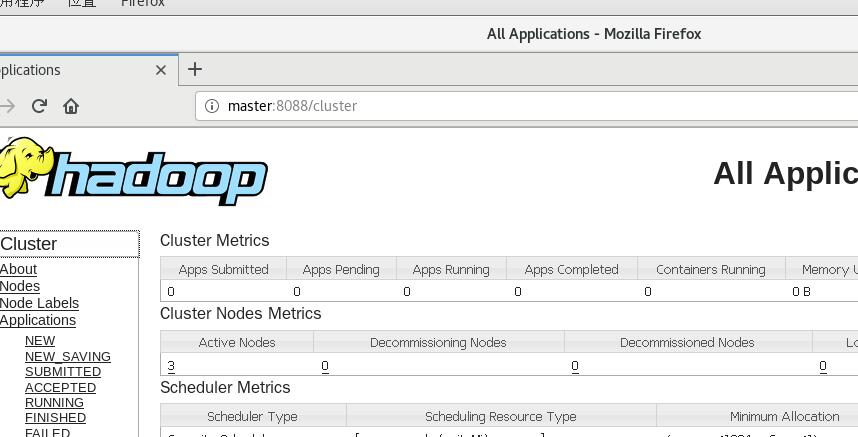
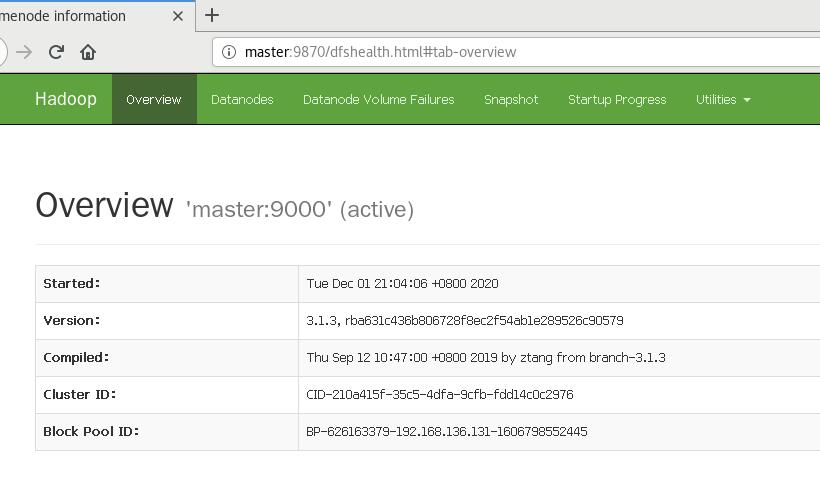
5.进入管理页面
在浏览器地址栏中输入以下命令
| 界面 | 地址 |
|---|---|
| 管理页面 | http://localhost:8088 |
| NameNode界面 | http://localhost:9870 |
4.Hadoop运行实例
进入hadoop-3.1.3目录
(1) 创建Input文件夹
1 | # hdfs dfs -mkdir /Input |
(2) 将test.txt文件上传到hdfs的/Input目录下
1 | # hdfs dfs -put LICENSE.txt /Input/test.txt |
(3) 运行hadoop安装包中自带的wordcount程序
1 | # hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /Input/test.txt /Output/ |